Benchmark of existing open source solutions for conflating structured, geographical and transit data
published on 21 April 2020 by Jungle Bus

More
and more open transport data is available today. To take full advantage
of this, the need for stable and durable identifiers is emerging:
whether to recognize and deduplicate similar objects from multiple
sources, to link or even enrich this data with other open data sets or
to define complex fare agreements, it is necessary to be able to
identify and retrieve an object with certainty through the available
data sources.
But each transport operator and local authority has
its own way of labeling and identifying its own data. In order to
provide a unique and immutable identifier for each useful notion in the
dataset, it will therefore be necessary to identify similar data across
several datasets.
The following study is a comparative review of different open source conflation solutions for comparing and merging data.
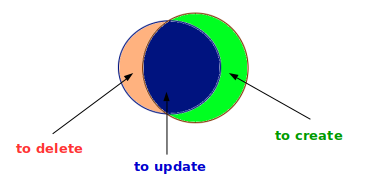
General principles
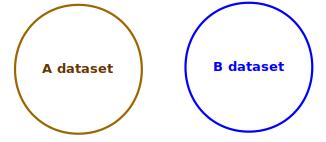
The
process of conflation can be explained as follows: it’s about comparing
the data from one source (source A) with the data from another source
(source B) according to a set of criteria to be finely defined. The
output of this process is a segmentation into three sets of data :
- the data available in both datasets
- the data available only in the initial dataset A
- the data present only in the second dataset B
The purpose is often to generate a merged dataset enhanced from
both initial datasets, but depending on the situation several operations
may be carried out with these datasets.
If there are two sets of
data on the same perimeter, the focus will be on the data identified in
both sets of data. The others will have to be monitored and will
potentially indicate errors or gaps in the sources or conflating
process.
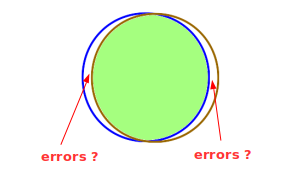
If
there are two partially overlapping datasets - for instance data from
the same transport network provided by the operator (source A) and the
transit authority (source B) that has a larger perimeter than the
network - it is expected that a large portion of the dataset from source
B will not be found in source A.
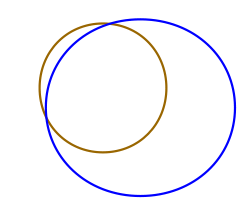
Finally,
if there is an update of the same dataset by the same provider, we may
for instance want to delete the data not found in the initial dataset
and create the new dataset.
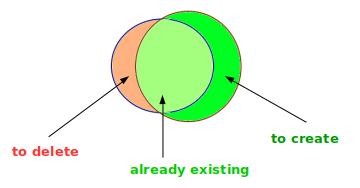
There
are many open source conflation tools for OpenStreetMap. The common use
case is to use a third party dataset (available under an open data
license compatible with the OpenStreetMap license) in order to enhance
the OpenStreetMap database.
After comparison, we want to identify
- data common to the datasets and use third-party source information to enrich existing objects in OpenStreetMap
- data existing only in the third party dataset, which are potentially
missing objects in OpenStreetMap that one would like to create
- data existing in OpenStreetMap but not in the third party dataset,
which may be obsolete or false data to be deleted (if the third party
dataset is exhaustive on the considered perimeter)
The
Wikidata project, although more recently launched, also has many
conflation tools that have a fairly similar working principle.
Finally, even if they do not have such a thriving open source ecosystem,
we will study some conflation solutions specific to transport data.
We won’t study all the conflation tools of these ecosystems, but only the ones that matches our use cases:
- conflating points (for instance stops)
- conflating non geographical notions (for instance an agency or a public transport mode)
- conflating a set of heterogeneous transport objects (because it may
be easier to conflate routes if you already have matched their network
first).
Here is the list of the tools that will be reviewed:
| Tool |
Ecosystem |
Object type |
| Conflation plugin for JOSM |
OSM |
Point |
| Osmose |
OSM |
Point |
| OSM Conflate |
OSM |
Point |
| OSM ↔ Wikidata |
OSM, Wikidata |
Point |
| Mix’n’match |
Wikidata |
Non geographic |
| OpenRefine |
Wikidata |
Non geographic |
| Ref-lignes-stif |
OSM, transport specific |
Transport objects |
| Tartare tools |
OSM, transport specific |
Transport objects |
| Go Sync |
OSM, transport specific |
Transport objects |
| gtfs2osm |
OSM, transport specific |
Transport objects |
Conflating geographical points
Geographic
points are elementary objects much used in cartography. Numerous open
source tools have been developed to compare and facilitate the
integration of point data in OpenStreetMap, from shops to various points
of interest.
In our use case, we may want to use this tools to
compare and match geographical points such as transport stops or subway
entrances.
JOSM Conflation plugin
In JOSM, the main desktop application for editing OpenStreetMap data, a plugin that performs conflation is available.
It processes two input datasets:
- the subject dataset: usually OpenStreetMap data already filtered (e.g. only bus stops)
- the reference dataset: usually an open data set (e.g. the stops.txt file of a GTFS file)
Both datasets are in OpenStreetMap format (osm XML).
The JOSM editor can load geojson and csv files and perform format
conversion. But most of the time, adjustments have to be made in the
reference dataset to match it with the data structure of OpenStreetMap.
For instance, we will transform:
file: stops.txt
| stop_id |
stop_name |
stop_lat |
stop_lon |
location_type |
parent_station |
| NAQ:Quay:44930 |
Séreilhac - Les Betoulles |
45.777938843 |
1.0951570272 |
0 |
NAQ:StopPlace:31168 |
to:
file: stops.csv
| highway |
name |
latitude |
longitude |
| bus_stop |
Séreilhac - Les Betoulles |
45.777938843 |
1.0951570272 |
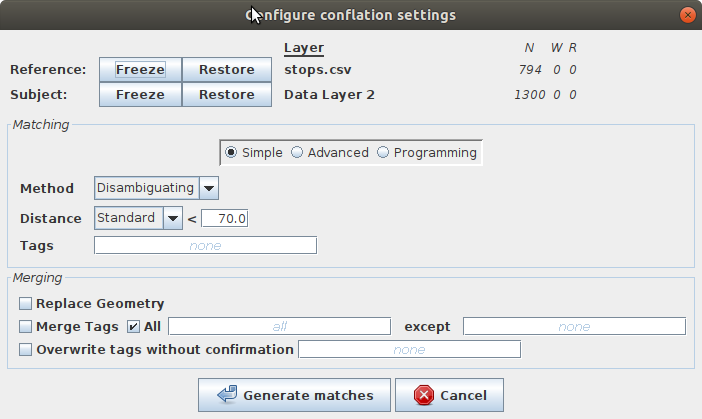
Several parameters should be set up to perform the data comparison:
- the method (only search for the closest element VS choose for each one an appropriate close element)
- the conflation distance
- the optional use of a reference tag that should already be in the two input datasets
Other advanced settings are also available for polygon comparison.
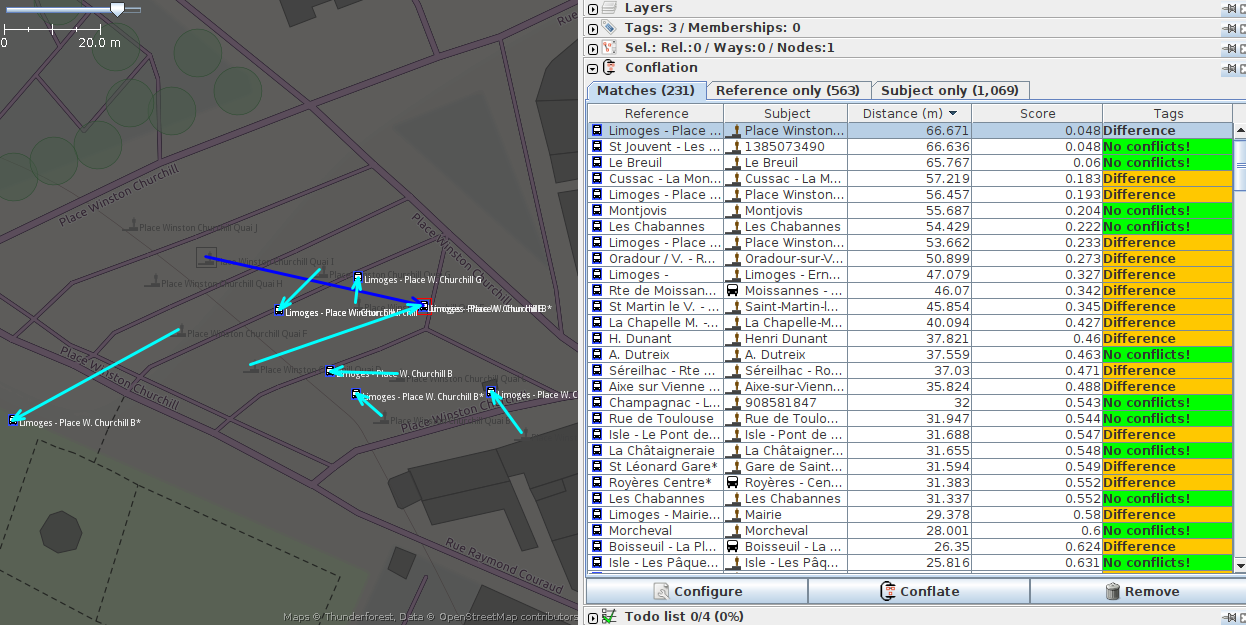
The output datasets are:
- “Matches” (elements found in both): we can see the distance and if
there are differences in the tags between the sources. In one click, we
can apply the tags or geometry of the object from the reference dataset
to the subject object (depending on the parameters chosen in the
configuration).
- “Reference only” (elements present only in the reference dataset):
In one click, you can create the element in the source dataset with the
attributes and geometry of the reference dataset.
- “Subject only” (elements present only in the subject dataset).
The source code is in Java and licensed under GPL v2 or later.
Osmose
Osmose QA
is a quality assurance tool for the OpenStreetMap database and it can
also be used to match data from open data sources and update
OpenStreetMap.
It takes as input a dataset (called “official”) in
various formats (csv, geojson, GTFS stops.txt file, etc) and an
OpenStreetMap database in .osm.pbf format.
You then
need to define which OpenStreetMap objects are candidates for the match
(OpenStreetMap type and set of tags) and to set up a conflation
distance.
If there is an unique and stable id in the official dataset that can be
added to OpenStreetMap, you can also use it for the conflation.
Then,
you have to map the attributes of the official data to OpenStreetMap
tags. Some are mandatory tags and some are secondary tags that are not
checked on updates.
The conflation process can output various datasets:
- “missing_official”: this object was found in the official dataset
but does not exist in OpenStreetMap. You can then add this object to
OpenStreetMap using Osmose web interface.
- “missing_osm”: this object from OpenStreetMap was not found in the
official dataset. If the official dataset is exhaustive, this object
should be removed from OpenStreetMap
- “possible_merge”: this object from OpenStreetMap may match an object
from the official dataset. You can add update its tags according to the
official dataset.
- “update_official” (only available if there is a stable id): this
object from OpenStreetMap matches an object from the official dataset.
You can update its mandatory tags according to the official dataset.
Note that a same OpenStreetMap object can be in multiple outputs
datasets: for instance, a valid existing object in OpenStreetMap
without id will be in both “possible_merge” and “missing_official”.
Osmose
is available “as a service” for OpenStreetMap contributors (as opposed
to a tool for individual use) and performs periodic updates to reflect
changes in the OpenStreetMap database and source dataset.
You can also export a merged dataset, containing the matched elements with OpenStreetMap attributes and location.
For example, this Osmose config file conflates train stations extracted from a GTFS feed to OpenStreetMap objects with railway=station or railway=halt tag.
(...)
self.init(
u"https://ressources.data.sncf.com/explore/dataset/sncf-ter-gtfs/",
u"Horaires prévus des trains TER",
GTFS(Source(attribution = u"SNCF", millesime = "08/2017",
fileUrl = u"https://ressources.data.sncf.com/explore/dataset/sncf-ter-gtfs/files/24e02fa969496e2caa5863a365c66ec2/download/")),
Load("stop_lon", "stop_lat",
select = {"stop_id": "StopPoint:OCETrain%"}),
Mapping(
select = Select(
types = ["nodes", "ways"],
tags = {"railway": ["station", "halt"]}),
osmRef = "uic_ref",
conflationDistance = 500,
generate = Generate(
static1 = {
"railway": "station",
"operator": "SNCF"},
static2 = {"source": self.source},
mapping1 = {"uic_ref": lambda res: res["stop_id"].split(":")[1][3:].split("-")[-1][:-1]},
mapping2 = {"name": lambda res: res["stop_name"].replace("gare de ", "")},
text = lambda tags, fields: {"en": fields["stop_name"][0].upper() + fields["stop_name"][1:]} )))
In this example, it uses as stable id:
- a part of the
stop_id from the GTFS for the official dataset
- the value of the
uic_ref tag for OpenStreetMap
For OpenStreetMap objects that does not have this tag, the distance used for the conflation is 500 meters.
Only the following outputs are proposed in Osmose web interface:
- possible_merge: the railway stations that exist in OpenStreetMap, have no
uic_ref and are at less than 500 meters from a railway station in the official dataset
- missing_osm: the railway stations that exist in OpenStreetMap but have a
uic_ref tag that was not found in the official dataset or that have no uic_ref tag and no railway station from the official dataset was found nearby
- missing_official: the railway stations from the official dataset for which no object in OpenStreetMap with an appropriate
uic_ref tag was found
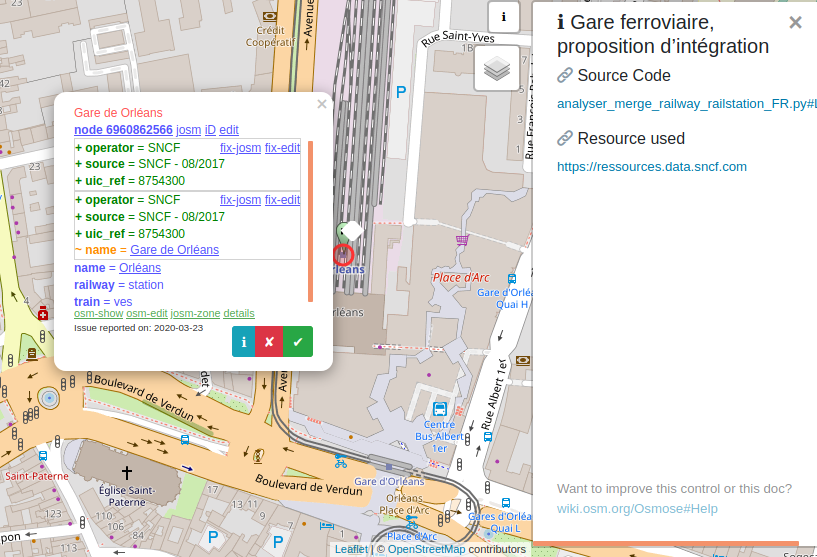
In Osmose web interface, you can review and edit each element to approve or amend the tag modifications that are suggested.
The source code is in Python and licensed under GPL v3.
OSM Conflate
OSM Conflate (also known as OSM Conflator) is a script to merge a dataset with OpenStreetMap data. It was developed by Maps.me, a Russian company that develops the Maps.Me
mobile application for travelers with offline maps and navigation from
OpenStreetMap data. Its main purpose is to update already existing
OpenStreetMap objects with attributes from the source dataset, and to
create missing ones.
You need to define a profile to conflate the
third-party dataset with OpenStreetMap, it can be a JSON file in simple
cases or a python file. OpenStreetMap data can be provided (as osm XML file) or gathered remotely using Overpass API with a query set in the profile.
It can use a stable id (called dataset_id)
to match objects from both datasets. If not set, it will find closest
OpenStreetMap objects for each object from the dataset using the
conflation distance set in the profile.
Its default output is an
OSM change file with OpenStreetMap modifications that can be uploaded to
OpenStreetMap with updated tags for the matched objects, new objects
for the elements present only in the source dataset and remaining
OpenStreetMap objects flagged with some special tag or deleted.
As
OpenStreetMap community has a strict policy on data import from other
sources and this use case is not recommended, you can also get a geojson
output format to review the changes, with the following output
datasets:
- blue: an OSM object was found, and its tags were modified
- green: no match in OSM was found, a new object was created
If the dataset_id was used, there are additional output datasets:
- Light red: OSM object had the
dataset_id tag, but was missing in the third-party dataset so the OSM object was deleted
- Dark red: same one, but don’t delete OSM object and retag it instead
- Dark blue: OSM object had the
dataset_id tag and was moved, because the point in the dataset was moved too far
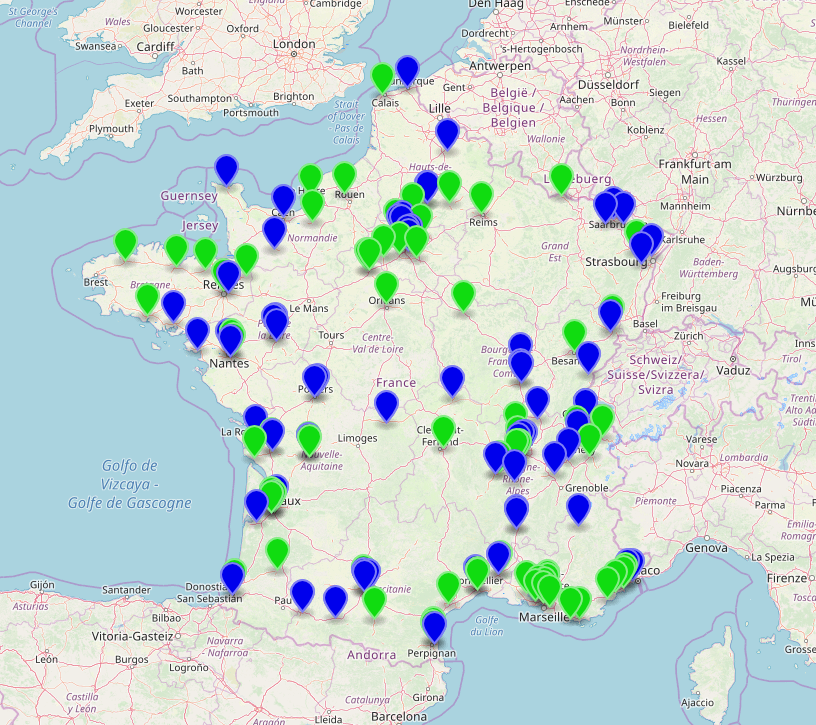
You
can review this file on your own or use the web interface (OSM
Conflator Audit System) to share the validation with the OpenStreetMap
community.
It allows OpenStreetMap users to check each element, and change the
proposed tags to be imported and location if needed. Once the whole
dataset has been reviewed, the results can be imported back in OSM
Conflate to create a new OSM change file.
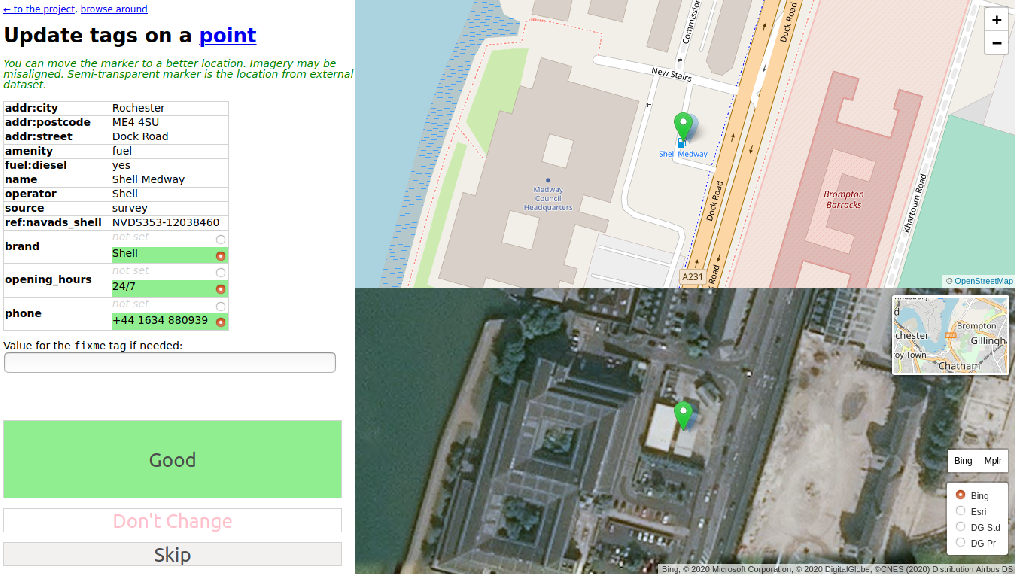
The source code is in Python and licensed under Apache-2.0.
OSM ↔ Wikidata
OSM ↔ Wikidata is yet another enrichment tool for OpenStreetMap. It allows to add the wikidata tag on OpenStreetMap objects (which represents the id of the Wikidata item about the feature).
It is therefore a particularly interesting tool in the context of our
study since it is about making a comparison between a structured base
(Wikidata) and a geographical base (OpenStreetMap) in order to add an
unique and stable identifier (the Wikidata identifier) on the objects of
the geographical base.
The principle is to select objects in Wikidata and search for their equivalent in OpenStreetMap.
The algorithm is not based on a distance search but works by
geographical area (for example a city or a neighborhood): all Wikidata
objects with the property P625 (coordinate location) are retrieved in
this area, then all OpenStreetMap candidate objects in this same area
are retrieved. The matching is based on name (for OpenStreetMap) and
English Wikipedia categories (for Wikidata objects).
We get as output:
- the objects found in both bases. They are further segmented into two categories:
- already tagged: those who already have a common wikidata id, that can be browsed and checked out
- match candidates: several OpenStreetMap objects can be found for
each Wikidata object. Additional information is compared and displayed
to the user who can then choose the best object in OpenStreetMap. The
user can then enrich the OpenStreetMap object by adding the
wikidata tag (position and other tags are not affected).
- no match : items with no match found in OSM
If a match is found, the following attributes are compared and displayed for match candidates:
- the location: property P625 for Wikidata, coordinates in OSM
- the names in different languages: labels for Wikidata,
name, (and name:en, name:fr, etc) tags for OSM
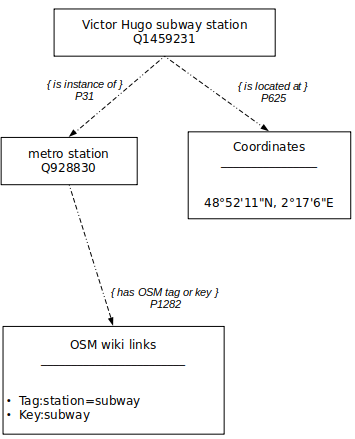
- the kind of object: the kind of object in Wikidata is the value of the property P31 (
is instance of). The property has itself a property P1282 (OSM key or tag)
- other identifiers if relevant (for instance, UIC codes for train
stations or IATA code for airport that can be set both in OpenStreetMap
and Wikidata)
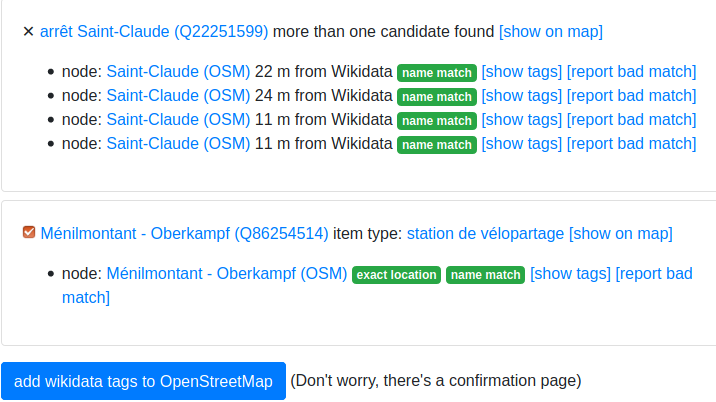
some match candidates
The source code is in Python and licensed under GPL v3.
Comparative review
All the conflation tools for geographical points studied here were from the OpenStreetMap ecosystem.
Their mechanism are quite similar :
You need to map your third-party dataset to the OpenStreetMap data model
(create a geographical point with the coordinate and transform the
attributes to OpenStreetMap tags)
Then, your conflation can be based on some unique and stable identifier
that is both in the third-party dataset and in OpenStreetMap. You will
use instead or in addition a conflation distance to find close elements
to match.
Only OSM ↔ Wikidata tool has a different approach and
try to maximize the number of OpenStreetMap candidates for each third
party element to make sure you can find the appropriate match despite
the differences in the data model.
Most of these tools needs you
to investigate each element to validate the match and/or propose some
kind of community review to go through the whole dataset. This is
characteristic of the way OpenStreetMap works: the project has a large
community and discourages massive data imports or modifications without
reviewing every single item.
As a result, the visualization of the
output is key to the success of the conflation and most tools displays
the distance or the tags differences.
On a whole dataset point of view, OSM Conflate and the Conflation plugin
offers the best visualization of the output datasets and are good
options to iterate to find the best conflation distance.
Osmose interface is better on the element point of view, to check the tags to add, remove or update on OpenStreetMap object.
Most
of these tools are designed for one-time integration. They can be used
to perform update but it would be manual process to design. Only Osmose
has some mechanism to periodically update both the third-party dataset
and the OpenStreetMap data and automatically perform again the
conflation. Its web interface even has graphical statistics about the
evolution of each output dataset.
|
JOSM Conflation plugin |
Osmose |
OSM Conflate |
OSM ↔ Wikidata |
| need to match the dataset with OSM model |
yes |
yes |
yes |
no |
| use an identifier existing in both dataset |
possible, not mandatory |
possible, not mandatory |
possible, not mandatory |
possible, not mandatory |
| investigate each output element |
needed |
needed |
possible and recommended |
needed |
| collaborative review |
not possible |
yes |
possible |
yes |
| visualization of the conflation output |
++ |
+ |
++ |
+ |
| visualization of each output element |
+ |
++ |
+ |
++ |
| language |
Java |
Python |
Python |
Python |
| user interface |
in JOSM |
dedicated web UI |
dedicated web UI |
web UI |
| license |
GPL v2 |
GPL v3 |
Apache-2.0 |
GPL v3 |
Conflating non geographical objects
Conflating
non geographical objects consists mainly in comparing strings of
characters, possibly standardized (without capital letters, accents,
abbreviations, etc). The Wikidata integration tools are the ones that
have taken this concept the furthest.
In our use case, we may want to use this tools to compare and match operators, networks or even transport lines or stations.
Mix’n’Match
Mix’n’match is an online tool to match external datasets to Wikidata.
It
takes some external dataset, call catalog, that contains a list of
entries, with some unique id. The objective is to match each element
with a Wikidata entry and to add the identifier of the catalogue to
Wikidata. It can also create new elements for elements that don’t exist
yet in Wikidata.
The conflation configuration does not need to
implement mapping with Wikidata as it only relies on id and name. You
can also define the Wikidata property for the catalog identifier and the
default type of the objects in the catalog (is it about humans, books,
train stations, etc)
A fuzzy match is performed on the name and the tool proposes the following outputs datasets that can be browsed by the users:
- blue: a match has been found, an user has to approve it to add the identifier in Wikidata
- red: no match found
The users can then collaboratively approve or reject the
proposed matches. An item can also me marked as irrelevant for Wikidata
import (useful for duplicates for instance).
In the end, there are five outputs datasets:
- manually matched
- automatically matched stilled to review
- not in Wikidata yet
- not applicable to Wikidata
- unmatched
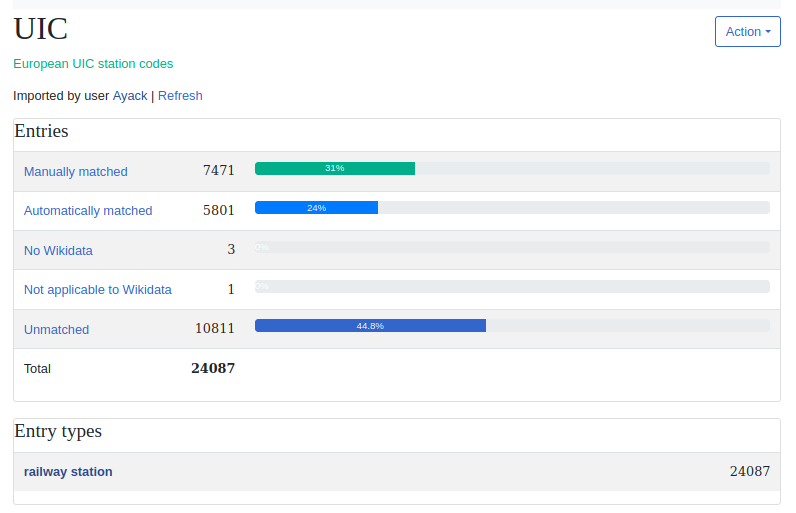
Current status of the import of the UIC catalog (that contains European train stations)
There is also a game mode where the user is presented to
a random element not matched yet, with the search results from both
Wikidata and Wikipedia projects and has to choose the most relevant item
for matching. Once chosen, the identifier is added to Wikidata and
another item is presented for review.
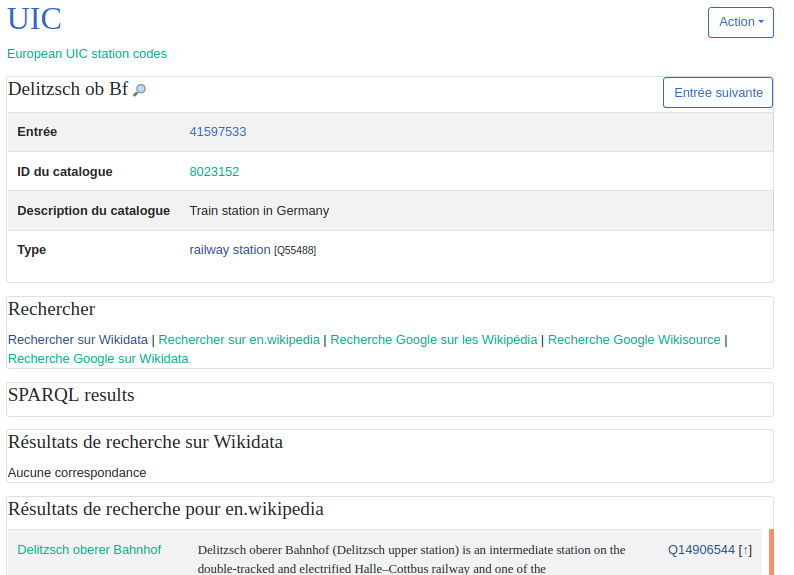
Here, we are matching the UIC catalog to Wikidata in game mode. The
current element “Delitzsch ob Bf” seems to be matching with “Delitzsch
oberer Bahnhof” that already exists in Wikidata and has a page in en.wikipedia.org
Mix’n’Match source code is in PHP and licensed under GPL v3.
OpenRefine & Reconcile-csv plugin for OpenRefine
OpenRefine
is a web desktop application to clean up messy dataset and perform
format conversion. It is widely used to prepare data import for
Wikidata.
OpenRefine’s reconciliation service can be used to
conflate non geographical objects. The service will take a dataset of
elements with some text (a name or a label) and return a ranked list of
potential objects matching the criteria from another remote database.
By default, this remote database is Wikidata, but other databases can be
added if they provide a compatible API (ORCID, Open Library, etc).
With the reconcile-csv plugin for OpenRefine, you can even use a csv
file as external database and use fuzzy matching on the labels.
You
can improve the conflation process by providing additional properties
to narrow down the research. For instance, when conflating a database of
books, the author name or the publication date are useful bits of
information that can be transferred to the reconciliation service. If
your database contains a unique identifier stored in Wikidata, you can
also use it in the conflation process.
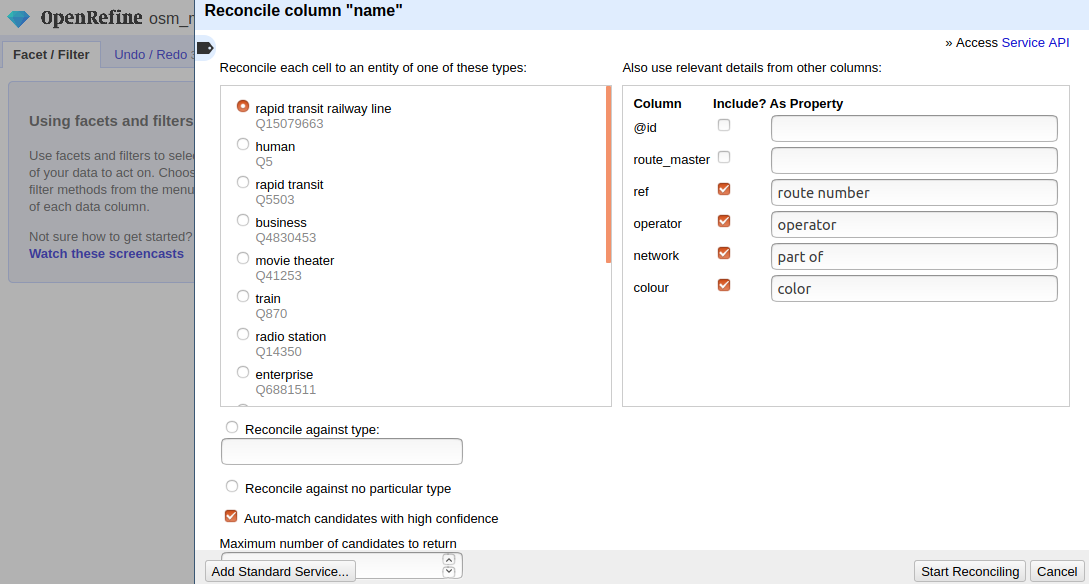
conflating subway lines from OpenStreetMap with Wikidata and match some tags to Wikidata properties to narrow down the search
As a result, you get several matching candidates for
each item, with a score: the likelihood the two compared elements are
the same.
You can then review each element, filter by score or automatically match each element with its best match.
You can also configure complex workflow to enhance your initial dataset with attributes from the remote dataset.
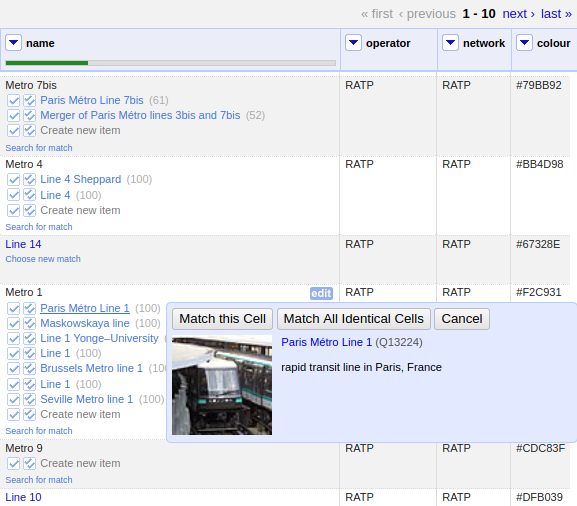
matching some subway lines from OpenStreetMap with Wikidata in OpenRefine
OpenRefine source code is in Java and licensed under BSD 3-Clause “Revised” License. Reconcile-csv source code is also in Java and released under BSD 2-Clause “Simplified” License.
Comparative review
Unlike
previous tools, which required precise mapping between attributes,
these tools require much less configuration and iteration. They perform
fuzzy name searches, taking great advantage of the ability to define
aliases for labels in the Wikidata database.
We find again the possibility to use an identifier for the matching (the Wikidata identifier).
These
tools also follow the paradigm of proposing several candidates if
possible rather than choosing the one that corresponds the most, leaving
the user to make the final decision.
|
Mix’n’Match |
OpenRefine & Reconcile-csv plugin for OpenRefine |
| need to match the dataset with OSM model |
partially |
partially |
| use an identifier present in both dataset |
yes |
possible, not mandatory |
| investigate each output element |
needed |
possible |
| collaborative review |
yes |
not possible |
| visualization of the conflation output |
++ |
- |
| visualization of each output element |
++ |
+ |
| language |
PHP |
Java |
| user interface |
web |
web |
| license |
GPL v3 |
BSD |
Conflating transport data
Conflating
transport data is about conflating both stops and routes, by using the
logical and hierarchical structuring of transport data to improve the
conflation process.
Most of the tools come from the OpenStreetMap
ecosystem and aim to use open data transport in GTFS format to update
OpenStreetMap.
GO Sync
GO Sync
(also called GTFS OSM Sync) is a desktop application to synchronize the
bus stop and route information from a GTFS dataset with OpenStreetMap.
It creates stop and route data in OpenStreetMap using GTFS information.
It was created in 2010 and uses a simplified data model for
OpenStreetMap route that is not in use anymore. It also only works for
buses.
It can be used both for initial data creation in OpenStreetMap and for updating.
It starts by conflating stops using
stop_id for GTFS and gtfs_id tag for OpenStreetMap as an identifieragency_name for GTFS and operator tag for OpenStreetMap (as an option)- a max distance as a parameter
Its output is segmented into four different groups:
- GTFS stops not found in OpenStreetMap and that can be added
- GTFS stops having possible conflicts with stops in OSM (a stop
exists in the OpenStreetMap database but does not have an associated
gtfs_id or has a geographic location that does not exactly match the location of a GTFS bus stop).
- GTFS stops which already exist in OSM but have updated information from the agency
- GTFS stops which are identical to OSM stops
The user can then review the results and add or update bus stop data to OpenStreetMap, using GTFS attributes.
It
also has a route conflation tool, that match GTFS route with
OpenStreetMap route relation (that is more of a line variant in the
latest data OpenStreetMap data model).
To conflate the route, it will use:
route_id for GTFS and gtfs_id tag for OpenStreetMap as an identifieragency_name for GTFS and operator tag on route for OpenStreetMaproute_short_name for GTFS and ref tag on route for OpenStreetMap- a bounding box created with the extent of the stops from the GTFS
It will output four datasets just like for the stops. If no
route is found, it can be created using the GTFS attributes and the
existing OpenStreetMap matched stops as members.
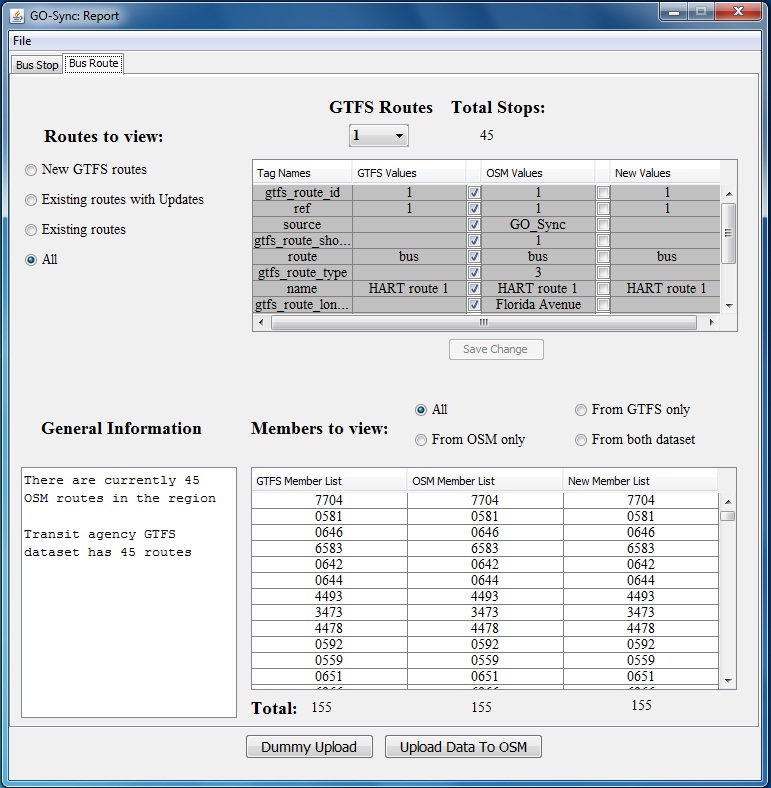
GO Sync source code is in Java and licensed under Apache-2.0.
Another more recent tool in the OpenStreetMap ecosystem exists with similar use cases: GTFS Integrate.
It allows to precisely map the GTFS attributes to OpenStreetMap ones in
order to prepare a data integration. It does not conflate much but is
focused on initializing OpenStreetMap data structures using available
information.
gtfs2osm
gtfs2osm
is a web-based tool for to create transport data in OpenStreetMap using
a GTFS. It has therefore some functions to compare the GTFS with the
already existing OpenStreetMap data in order to avoid the creation of
duplicates objects.
It is in the form of a script that creates web
pages by recursively browsing GTFS objects. It takes as input a GTFS
file and an OpenStreetMap database in osm.pbf format. We
will look at the original version (originally thought for the Paris
region) as well as a more recent version (thought for Luxembourg),
although there is not really any specificity for some geographical area
or network in this tool.
The website proposes to explore the GTFS by first choosing a mode of transport (GTFS route_type) among those available, then a transport agency, then a line (GTFS route), then a line variant (GTFS trip,
knowing that the trips entirely included in another are filtered out).
It is on this line variant page that the use really begins.
For
each GTFS stop on this trip, several OpenStreetMap candidates objects
are explored by the script, which will finally choose the closest
OpenStreetMap stop, or a nearby stop with exactly the same name, or
nothing if no candidates are found.
The search for candidate OpenStreetMap objects is based on several tags
chosen according to the mode of transport, in order to take into account
the diversity of contributions in OpenStreetMap (where several
transport models coexist)
Only one candidate is presented, with
information on the distance and similarity of the name. The user can
then import this object into JOSM OpenStreetMap editor, and
automatically add an additional number of tags.

The user can also create in one click in JOSM the OpenStreetMap object corresponding to the trip (a route relation) based on the information present in the GTFS.
Going
up in the breadcrumb trail, the user is returned to the line page,
where they are shown the OpenStreetMap objects that could match (route_master
relations) with a matching mode of transport, line number and transport
network, or with a matching identifier present in both OpenStreetMap
and GTFS. If no candidate is found, the user can create the
OpenStreetMap object in JOSM in one click using the information from the
GTFS.
gtfs2osm source code is in Perl and licensed under GPL v3.
ref-lignes-stif
ref-lignes-stif
(also called STIF-to-OSM) is a web interface to compare and add unique
identifier to OpenStreetMap transport objects in Île-de-France (Paris
region).
The local authority of the Paris region (who was called
STIF when the tool was initially released) has defined unique
identifiers for each public transport line (~ 1800) and stop (~40 000).
The tool helps OSM contributors to add these identifiers to
OpenStreetMap objects in a guided workflow: matching lines, then line
variants, then stops. It is a web tool and it uses Overpass web service
to query OpenStreetMap and navitia.io API to get public transport objects.
The
entry point is a searchable list of lines from OpenStreetMap. When you
select a line, the tools presents you open data candidates based on the
line number. For the 91-10 bus line, you will only get one candidate
while for a bus line labelled “2” you will get 19 results to review.
For each candidate, you can review its attributes, its shape and its stops from both OpenStreetMap et Paris region open data.
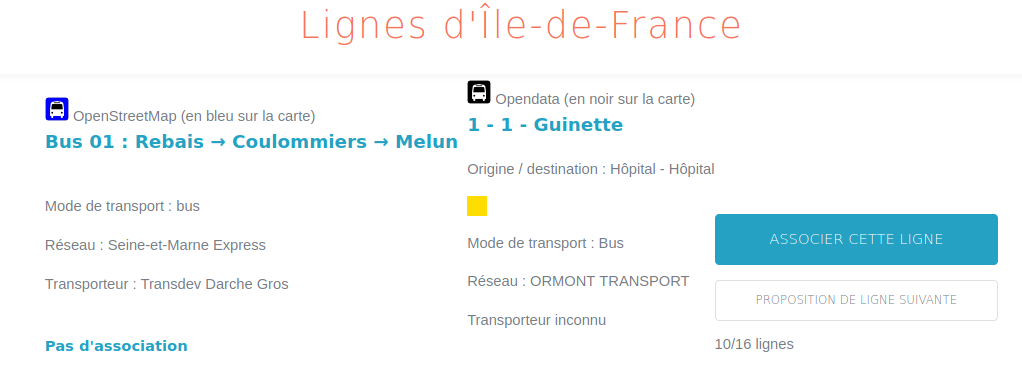
The
user has to choose the best match within the proposals: the open data
line identifier will be retrieved and added to OpenStreetMap, and the
user will access the line variant review page.
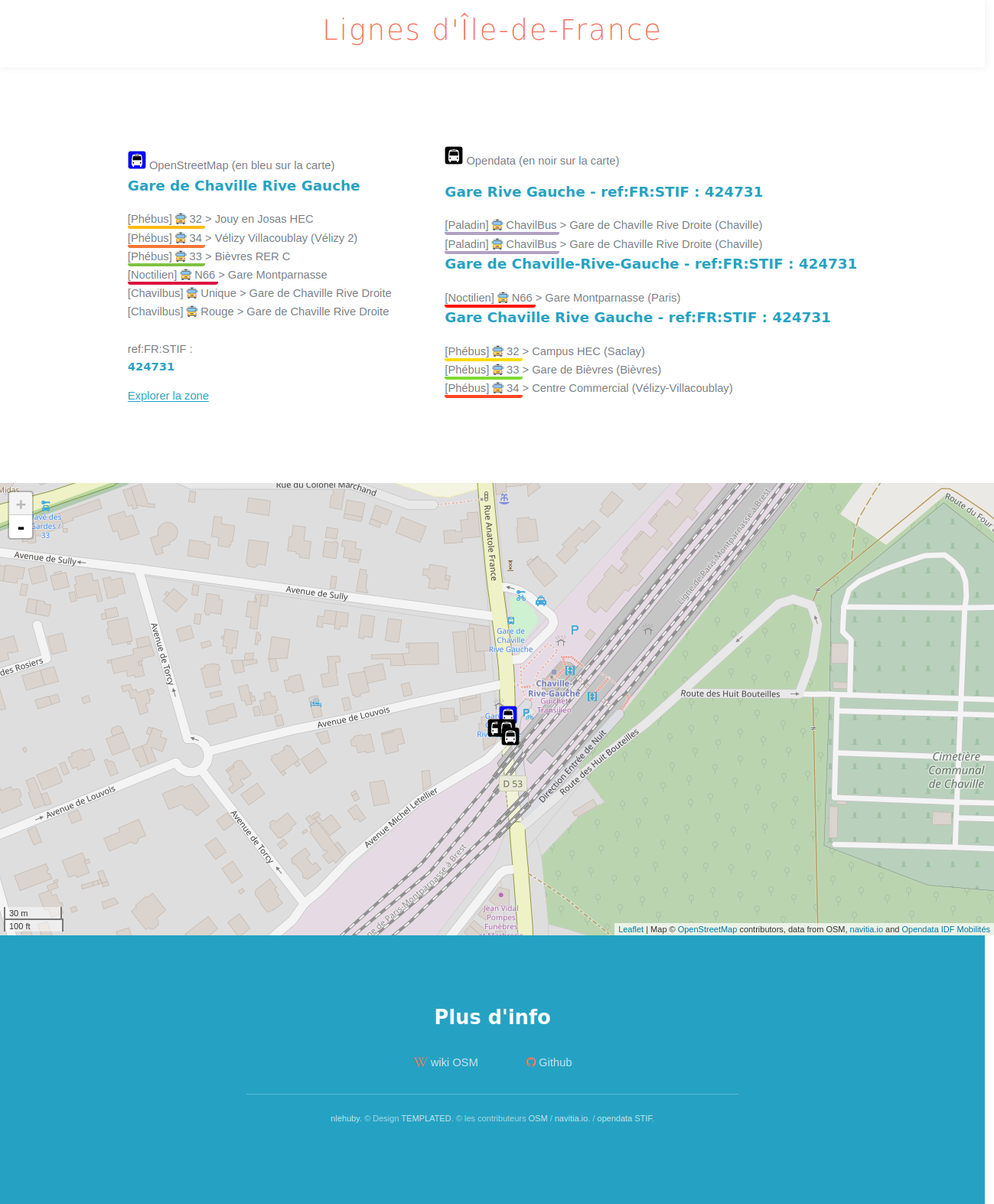
On this page, you
get the list of the line variants from OpenStreetMap and you have to
choose between the line variants from the open dataset. In most cases,
in both OpenStreetMap and the open dataset, the line variants have their
origin and destination as labels, so you can easily choose the good
one. A debug page is available to see the shapes and stops from
OpenStreetMap and the stops from the open dataset for each line variant
to help the user to make the right choice.
As there is no line variant identifier in the open dataset, no
identifier is added to OpenStreetMap, but the user can then access the
stop review page.
On the stop review page, you get the list of the
stops of the chosen line variant, and for each one, the closest open
data stop which is served by the open data line variant previously
chosen. You can compare their names and distance and automatically
retrieve and add the open data identifier in OpenStreetMap to the stop.
The web tool comes along with debug tools for each step:
- line debug view, to visualize line attributes, shapes and stops from both sources
- line variant debug view, to visualize route attributes, shapes and stops from both sources
- stop debug view, to visualize name, position and all line variants that serve the stops for both sources
- geographical debug view, to visualize all stops in an area, with names and line variants that serve each stops in both sources
The source code is in Javascript and released under the MIT license.
Tartare-tools
is a library to read transport data and perform format conversion. It
also has some functions to improve data using OpenStreetMap data. It was
developed by Kisio Digital, a French company that provides digital
services to simplify travel for passengers.
It takes as input a transport dataset in a custom format and an OpenStreetMap database in .osm.pbf format. It can
- add line and line variant shapes from OpenStreetMap to the transport dataset
- change location of the stops using OpenStreetMap
The library has a function to automatically match the transport
objects (lines, line variants and stops) to OpenStreetMap objects but
you can also provide some or all matchings to use the enhancements
functions.
You need to provide as configuration the matching between the transport dataset network and OpenStreetMap network.
The library will first match OpenStreetMap lines (as route_master relation objects) using:
- the network matching provided
- the line code from the transport dataset and the
ref tag from OpenStreetMap
If there is only one candidate, it will then match the line variants (called route in the library, as in OpenStreetMap) with OpenStreetMap line variant (as route relation objects) using:
- the number of stops from both sources
- the destination of the line variant: as the last stop for the transport dataset and using the
to tag from OpenStreetMap routes
If there is only one candidate, it will then match the stops of
the line variant with OpenStreetMap stops using the name. As for other
objects, the matching is valid only if there is only one candidate.
The
library is designed to require very little configuration (only network
matching) and has very strict conditions to limit false positives. It is
therefore not necessarily intended to match the entirety of the
objects. The number of objects actually matched will depend on the
quality of the OpenStreetMap data in terms of conformity to the model,
completeness and uniformity of the attributes filled in.
Tartare-tools source code is in Rust and licensed under GPL v3.
Other approaches
Sophox
Sophox
is a web tool that allows to query OpenStreetMap data, some
OpenStreetMap metadata and Wikidata data at the same time. It stores all
these data in a structured semantic way, using subject predicate object statements.
By
doing cross queries, it allows, for example, to find similar objects in
OpenStreetMap and Wikidata using a common identifier (the Wikidata
identifier) and to compare their attributes. For example, here is a
query comparing the attributes of subway lines:
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX hint: <http://www.bigdata.com/queryHints#>
SELECT DISTINCT ?wikidata_id ?osm_id ?label ?wikidata_color ?osm_color ?wikidata_operatorlabel ?osm_operator ?wikidata_networklabel ?osm_network WHERE {
hint:Query hint:optimizer "None".
SERVICE <https://query.wikidata.org/sparql> {
?wikidata_id wdt:P31 wd:Q15079663.
?wikidata_id wdt:P17 wd:Q142.
?wikidata_id rdfs:label ?label.
OPTIONAL { ?wikidata_id wdt:P465 ?wikidata_color. }
OPTIONAL {
?wikidata_id wdt:P137 ?wikidata_operator.
?wikidata_operator rdfs:label ?wikidata_operatorlabel.
FILTER((LANG(?wikidata_operatorlabel)) = "fr")
}
OPTIONAL {
?wikidata_id wdt:P361 ?wikidata_network.
?wikidata_network rdfs:label ?wikidata_networklabel.
FILTER((LANG(?wikidata_networklabel)) = "fr")
}
FILTER((LANG(?label)) = "fr")
}
OPTIONAL {
?osm_id osmt:wikidata ?wikidata_id.
?osm_id osmm:type "r".
?osm_id osmt:type "route_master".
?osm_id osmt:operator ?osm_operator.
?osm_id osmt:network ?osm_network.
?osm_id osmt:colour ?osm_color.
}
}
Using this approach for conflation seems complex, but it
could help identify errors or generate new composite datasets mixing
sources.
Sophox source code is licensed under Apache-2.0.
Transitland onestop ID
Transitland
is a community edited website and webservices aggregating transport
databases. To link datasets, operators, stops and routes across
disparate sources, it uses a mechanism called “Onestop ID scheme”.
This
mechanism consists of assigning a unique, perennial and readable
identifier, independent of the identifiers already present in the source
data. It is mainly based on a geohash and an abbreviated name and is
not really designed to effectively compare and merge datasets.
In the context of comparing and improving data from different sources, the practice of map matching is also sometimes used.
This generally involves bringing together data of quite different
natures (usually a series of geographic coordinates and a road or rail
network). For example, several tools attempt to use the OpenStreetMap
road network to complete transport routes independently of the
structured transport data in OpenStreetMap.
The objectives are diverse but quite different from our use case:
- creating missing shapes in GTFS data using OpenStreetMap street or rail network (for instance, pfaedle)
- creating missing shapes in OpenStreetMap using the stops sequence from another source (for instance ref-lignes-stif)
- etc
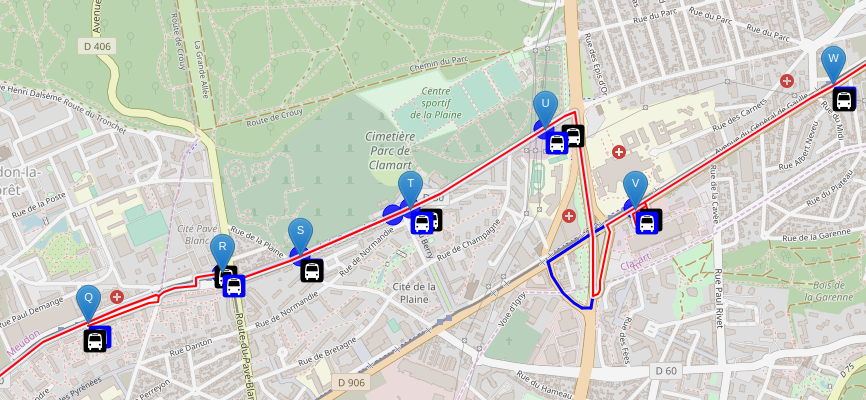
ref-lignes-stif can use the stops sequence from a GTFS route to
compute a shape, and then map match it with OpenStreetMap bus road
network to help OpenStreetMap contributors to create the shape in
OpenStreetMap
Comparative review
There
are two kinds of tools that use the logical and hierarchical
structuring of transport data to improve the conflation process:
- the tools that start with stops, then lines
- the tools that start with lines, then stop
Those who start with stops (gtfs2osm, GO Sync, GTFS Integrate)
match the stops from both sources using the methods described in the
“conflating geographical points” paragraph above. Then they create the
routes and lines if necessary using methods similar to those described
in the “Conflating non geographical objects” paragraph.
The use
case here is more focused on creating data in OpenStreetMap than on
conflation. The main interest of these tools is in the ability to
initialize OpenStreetMap objects using GTFS attributes and without
necessarily having a deep knowledge of the GTFS format.
Starting with the stops is also a form of prerequisite because the stops
are needed to create the objects representing the lines in
OpenStreetMap.
In contrast, those that start with lines are more focused on conflation than on creation of missing data.
The main interest of this approach is for bus stops, where associating
stops on either side of the road (which have a close distance and
similar attributes) is unefficient with traditional point conflation
approaches. By using the line variants that serve these stops, the risk
of mismatching is therefore reduced.
The two tools studied have
different approaches: Tartare-tools will rather minimize the risk of
false positive, even if it means not proposing an association at all,
while ref-lignes-stif will maximize the number of candidates proposed
for each association in order to be able to find a match for each
object, even if it means having the user make all the choices and spend a
lot of time at it.
In any case, these tools offer interesting insights on visualizing transport data from various sources.
|
GO Sync |
gtfs2osm |
ref-lignes-stif |
Tartare-tools |
| conflation process |
stops > routes |
stops > line variants > lines |
line > line variants > stops |
networks > lines > line variants > stops |
| need to match the dataset with OSM model |
yes |
no |
no |
partially |
| use an identifier present in both dataset |
yes |
possible |
yes |
not possible |
| investigate each output element |
yes |
yes |
needed |
no |
| collaborative review |
no |
yes |
yes |
not possible |
| visualization of the conflation output |
- |
+ |
- |
no |
| visualization of each output element |
+ |
+ |
++ |
no |
| language |
Java |
Perl |
Javascript |
Rust |
| user interface |
desktop application |
web |
web |
no |
| license |
Apache-2.0 |
GPL v3 |
MIT |
GPL v3 |
Conclusion
There are well-established mechanisms for performing data conflation:
- for geographic points, using one or more attributes and a conflation distance
- for non-geographic objects, by fuzzy searching and relying on aliases and synonyms
In the case of transport data, using the transport model
hierarchy greatly improves the quality of the process by limiting false
positives, but may be sensitive to modeling discrepancies.
Using
an identifier to link datasets is a proven technique found almost
systematically. It is also a good solution for maintenance over time,
which is critical for a database edited collaboratively by several
actors and very relevant in the context of evolving transport data.
While
many tools exist in OpenStreetMap and Wikidata collaborative databases
ecosystems, no single tool can meet all needs, due to the diversity of
use cases.
The main choice to be made according to the use case
will be to propose several candidates for each object (which implies a
more or less long and tedious work of reviewing each element) or,
conversely, to assign the best candidate to each object.
A review may remain proposed in any cases, and may be collaborative or not.
Whatever
the algorithm and process, special attention must be paid to the
visualization of the results, whether it is the individual debugging of
the matching of one element, or the global visualization of the results
and the percentage of objects in each category.
Credits
This study was carried out by Jungle Bus for MobilityData as part of the Mobility Database project.

This document is made available under the conditions of the CC-BY-SA license.

References
Benchmark of existing open source solutions for conflating structured, geographical and transit data
More and more open transport data is available today. To take full advantage of this, the need for stable and durable identifiers is emerging: whether to recognize and deduplicate similar objects from multiple sources, to link or even enrich this data with other open data sets or to define complex fare agreements, it is necessary to be able to identify and retrieve an object with certainty through the available data sources.
But each transport operator and local authority has its own way of labeling and identifying its own data. In order to provide a unique and immutable identifier for each useful notion in the dataset, it will therefore be necessary to identify similar data across several datasets.
The following study is a comparative review of different open source conflation solutions for comparing and merging data.
General principles
The process of conflation can be explained as follows: it’s about comparing the data from one source (source A) with the data from another source (source B) according to a set of criteria to be finely defined. The output of this process is a segmentation into three sets of data :
The purpose is often to generate a merged dataset enhanced from both initial datasets, but depending on the situation several operations may be carried out with these datasets.
If there are two sets of data on the same perimeter, the focus will be on the data identified in both sets of data. The others will have to be monitored and will potentially indicate errors or gaps in the sources or conflating process.
If there are two partially overlapping datasets - for instance data from the same transport network provided by the operator (source A) and the transit authority (source B) that has a larger perimeter than the network - it is expected that a large portion of the dataset from source B will not be found in source A.
Finally, if there is an update of the same dataset by the same provider, we may for instance want to delete the data not found in the initial dataset and create the new dataset.
Tools studied
There are many open source conflation tools for OpenStreetMap. The common use case is to use a third party dataset (available under an open data license compatible with the OpenStreetMap license) in order to enhance the OpenStreetMap database.
After comparison, we want to identify
The Wikidata project, although more recently launched, also has many conflation tools that have a fairly similar working principle.
Finally, even if they do not have such a thriving open source ecosystem, we will study some conflation solutions specific to transport data.
We won’t study all the conflation tools of these ecosystems, but only the ones that matches our use cases:
Here is the list of the tools that will be reviewed:
Conflating geographical points
Geographic points are elementary objects much used in cartography. Numerous open source tools have been developed to compare and facilitate the integration of point data in OpenStreetMap, from shops to various points of interest.
In our use case, we may want to use this tools to compare and match geographical points such as transport stops or subway entrances.
JOSM Conflation plugin
In JOSM, the main desktop application for editing OpenStreetMap data, a plugin that performs conflation is available.
It processes two input datasets:
Both datasets are in OpenStreetMap format (osm XML). The JOSM editor can load geojson and csv files and perform format conversion. But most of the time, adjustments have to be made in the reference dataset to match it with the data structure of OpenStreetMap.
For instance, we will transform:
file:
stops.txtto:
file:
stops.csvSeveral parameters should be set up to perform the data comparison:
Other advanced settings are also available for polygon comparison.
The output datasets are:
The source code is in Java and licensed under GPL v2 or later.
Osmose
Osmose QA is a quality assurance tool for the OpenStreetMap database and it can also be used to match data from open data sources and update OpenStreetMap.
It takes as input a dataset (called “official”) in various formats (csv, geojson, GTFS stops.txt file, etc) and an OpenStreetMap database in
.osm.pbfformat.You then need to define which OpenStreetMap objects are candidates for the match (OpenStreetMap type and set of tags) and to set up a conflation distance.
If there is an unique and stable id in the official dataset that can be added to OpenStreetMap, you can also use it for the conflation.
Then, you have to map the attributes of the official data to OpenStreetMap tags. Some are mandatory tags and some are secondary tags that are not checked on updates.
The conflation process can output various datasets:
Note that a same OpenStreetMap object can be in multiple outputs datasets: for instance, a valid existing object in OpenStreetMap without id will be in both “possible_merge” and “missing_official”.
Osmose is available “as a service” for OpenStreetMap contributors (as opposed to a tool for individual use) and performs periodic updates to reflect changes in the OpenStreetMap database and source dataset.
You can also export a merged dataset, containing the matched elements with OpenStreetMap attributes and location.
For example, this Osmose config file conflates train stations extracted from a GTFS feed to OpenStreetMap objects with railway=station or railway=halt tag.
(...) self.init( u"https://ressources.data.sncf.com/explore/dataset/sncf-ter-gtfs/", u"Horaires prévus des trains TER", GTFS(Source(attribution = u"SNCF", millesime = "08/2017", fileUrl = u"https://ressources.data.sncf.com/explore/dataset/sncf-ter-gtfs/files/24e02fa969496e2caa5863a365c66ec2/download/")), Load("stop_lon", "stop_lat", select = {"stop_id": "StopPoint:OCETrain%"}), Mapping( select = Select( types = ["nodes", "ways"], tags = {"railway": ["station", "halt"]}), osmRef = "uic_ref", conflationDistance = 500, generate = Generate( static1 = { "railway": "station", "operator": "SNCF"}, static2 = {"source": self.source}, mapping1 = {"uic_ref": lambda res: res["stop_id"].split(":")[1][3:].split("-")[-1][:-1]}, mapping2 = {"name": lambda res: res["stop_name"].replace("gare de ", "")}, text = lambda tags, fields: {"en": fields["stop_name"][0].upper() + fields["stop_name"][1:]} )))In this example, it uses as stable id:
stop_idfrom the GTFS for the official datasetuic_reftag for OpenStreetMapFor OpenStreetMap objects that does not have this tag, the distance used for the conflation is 500 meters.
Only the following outputs are proposed in Osmose web interface:
uic_refand are at less than 500 meters from a railway station in the official datasetuic_reftag that was not found in the official dataset or that have nouic_reftag and no railway station from the official dataset was found nearbyuic_reftag was foundThe source code is in Python and licensed under GPL v3.
OSM Conflate
OSM Conflate (also known as OSM Conflator) is a script to merge a dataset with OpenStreetMap data. It was developed by Maps.me, a Russian company that develops the Maps.Me mobile application for travelers with offline maps and navigation from OpenStreetMap data. Its main purpose is to update already existing OpenStreetMap objects with attributes from the source dataset, and to create missing ones.
You need to define a profile to conflate the third-party dataset with OpenStreetMap, it can be a JSON file in simple cases or a python file. OpenStreetMap data can be provided (as
osm XMLfile) or gathered remotely using Overpass API with a query set in the profile.It can use a stable id (called
dataset_id) to match objects from both datasets. If not set, it will find closest OpenStreetMap objects for each object from the dataset using the conflation distance set in the profile.Its default output is an OSM change file with OpenStreetMap modifications that can be uploaded to OpenStreetMap with updated tags for the matched objects, new objects for the elements present only in the source dataset and remaining OpenStreetMap objects flagged with some special tag or deleted.
As OpenStreetMap community has a strict policy on data import from other sources and this use case is not recommended, you can also get a geojson output format to review the changes, with the following output datasets:
If the
dataset_idwas used, there are additional output datasets:dataset_idtag, but was missing in the third-party dataset so the OSM object was deleteddataset_idtag and was moved, because the point in the dataset was moved too farYou can review this file on your own or use the web interface (OSM Conflator Audit System) to share the validation with the OpenStreetMap community.
It allows OpenStreetMap users to check each element, and change the proposed tags to be imported and location if needed. Once the whole dataset has been reviewed, the results can be imported back in OSM Conflate to create a new OSM change file.
The source code is in Python and licensed under Apache-2.0.
OSM ↔ Wikidata
OSM ↔ Wikidata is yet another enrichment tool for OpenStreetMap. It allows to add the
wikidatatag on OpenStreetMap objects (which represents the id of the Wikidata item about the feature).It is therefore a particularly interesting tool in the context of our study since it is about making a comparison between a structured base (Wikidata) and a geographical base (OpenStreetMap) in order to add an unique and stable identifier (the Wikidata identifier) on the objects of the geographical base.
The principle is to select objects in Wikidata and search for their equivalent in OpenStreetMap.
The algorithm is not based on a distance search but works by geographical area (for example a city or a neighborhood): all Wikidata objects with the property P625 (coordinate location) are retrieved in this area, then all OpenStreetMap candidate objects in this same area are retrieved. The matching is based on name (for OpenStreetMap) and English Wikipedia categories (for Wikidata objects).
We get as output:
wikidatatag (position and other tags are not affected).If a match is found, the following attributes are compared and displayed for match candidates:
name, (andname:en,name:fr, etc) tags for OSMis instance of). The property has itself a property P1282 (OSM key or tag)The source code is in Python and licensed under GPL v3.
Comparative review
All the conflation tools for geographical points studied here were from the OpenStreetMap ecosystem.
Their mechanism are quite similar :
You need to map your third-party dataset to the OpenStreetMap data model (create a geographical point with the coordinate and transform the attributes to OpenStreetMap tags)
Then, your conflation can be based on some unique and stable identifier that is both in the third-party dataset and in OpenStreetMap. You will use instead or in addition a conflation distance to find close elements to match.
Only OSM ↔ Wikidata tool has a different approach and try to maximize the number of OpenStreetMap candidates for each third party element to make sure you can find the appropriate match despite the differences in the data model.
Most of these tools needs you to investigate each element to validate the match and/or propose some kind of community review to go through the whole dataset. This is characteristic of the way OpenStreetMap works: the project has a large community and discourages massive data imports or modifications without reviewing every single item.
As a result, the visualization of the output is key to the success of the conflation and most tools displays the distance or the tags differences.
On a whole dataset point of view, OSM Conflate and the Conflation plugin offers the best visualization of the output datasets and are good options to iterate to find the best conflation distance.
Osmose interface is better on the element point of view, to check the tags to add, remove or update on OpenStreetMap object.
Most of these tools are designed for one-time integration. They can be used to perform update but it would be manual process to design. Only Osmose has some mechanism to periodically update both the third-party dataset and the OpenStreetMap data and automatically perform again the conflation. Its web interface even has graphical statistics about the evolution of each output dataset.
Conflating non geographical objects
Conflating non geographical objects consists mainly in comparing strings of characters, possibly standardized (without capital letters, accents, abbreviations, etc). The Wikidata integration tools are the ones that have taken this concept the furthest.
In our use case, we may want to use this tools to compare and match operators, networks or even transport lines or stations.
Mix’n’Match
Mix’n’match is an online tool to match external datasets to Wikidata.
It takes some external dataset, call catalog, that contains a list of entries, with some unique id. The objective is to match each element with a Wikidata entry and to add the identifier of the catalogue to Wikidata. It can also create new elements for elements that don’t exist yet in Wikidata.
The conflation configuration does not need to implement mapping with Wikidata as it only relies on id and name. You can also define the Wikidata property for the catalog identifier and the default type of the objects in the catalog (is it about humans, books, train stations, etc)
A fuzzy match is performed on the name and the tool proposes the following outputs datasets that can be browsed by the users:
The users can then collaboratively approve or reject the proposed matches. An item can also me marked as irrelevant for Wikidata import (useful for duplicates for instance).
In the end, there are five outputs datasets:
There is also a game mode where the user is presented to a random element not matched yet, with the search results from both Wikidata and Wikipedia projects and has to choose the most relevant item for matching. Once chosen, the identifier is added to Wikidata and another item is presented for review.
Mix’n’Match source code is in PHP and licensed under GPL v3.
OpenRefine & Reconcile-csv plugin for OpenRefine
OpenRefine is a web desktop application to clean up messy dataset and perform format conversion. It is widely used to prepare data import for Wikidata.
OpenRefine’s reconciliation service can be used to conflate non geographical objects. The service will take a dataset of elements with some text (a name or a label) and return a ranked list of potential objects matching the criteria from another remote database.
By default, this remote database is Wikidata, but other databases can be added if they provide a compatible API (ORCID, Open Library, etc).
With the reconcile-csv plugin for OpenRefine, you can even use a csv file as external database and use fuzzy matching on the labels.
You can improve the conflation process by providing additional properties to narrow down the research. For instance, when conflating a database of books, the author name or the publication date are useful bits of information that can be transferred to the reconciliation service. If your database contains a unique identifier stored in Wikidata, you can also use it in the conflation process.
As a result, you get several matching candidates for each item, with a score: the likelihood the two compared elements are the same.
You can then review each element, filter by score or automatically match each element with its best match.
You can also configure complex workflow to enhance your initial dataset with attributes from the remote dataset.
OpenRefine source code is in Java and licensed under BSD 3-Clause “Revised” License. Reconcile-csv source code is also in Java and released under BSD 2-Clause “Simplified” License.
Comparative review
Unlike previous tools, which required precise mapping between attributes, these tools require much less configuration and iteration. They perform fuzzy name searches, taking great advantage of the ability to define aliases for labels in the Wikidata database.
We find again the possibility to use an identifier for the matching (the Wikidata identifier).
These tools also follow the paradigm of proposing several candidates if possible rather than choosing the one that corresponds the most, leaving the user to make the final decision.
Conflating transport data
Conflating transport data is about conflating both stops and routes, by using the logical and hierarchical structuring of transport data to improve the conflation process.
Most of the tools come from the OpenStreetMap ecosystem and aim to use open data transport in GTFS format to update OpenStreetMap.
GO Sync
GO Sync (also called GTFS OSM Sync) is a desktop application to synchronize the bus stop and route information from a GTFS dataset with OpenStreetMap. It creates stop and route data in OpenStreetMap using GTFS information. It was created in 2010 and uses a simplified data model for OpenStreetMap route that is not in use anymore. It also only works for buses.
It can be used both for initial data creation in OpenStreetMap and for updating.
It starts by conflating stops using
stop_idfor GTFS andgtfs_idtag for OpenStreetMap as an identifieragency_namefor GTFS andoperatortag for OpenStreetMap (as an option)Its output is segmented into four different groups:
gtfs_idor has a geographic location that does not exactly match the location of a GTFS bus stop).The user can then review the results and add or update bus stop data to OpenStreetMap, using GTFS attributes.
It also has a route conflation tool, that match GTFS route with OpenStreetMap route relation (that is more of a line variant in the latest data OpenStreetMap data model).
To conflate the route, it will use:
route_idfor GTFS andgtfs_idtag for OpenStreetMap as an identifieragency_namefor GTFS andoperatortag on route for OpenStreetMaproute_short_namefor GTFS andreftag on route for OpenStreetMapIt will output four datasets just like for the stops. If no route is found, it can be created using the GTFS attributes and the existing OpenStreetMap matched stops as members.
GO Sync source code is in Java and licensed under Apache-2.0.
Another more recent tool in the OpenStreetMap ecosystem exists with similar use cases: GTFS Integrate.
It allows to precisely map the GTFS attributes to OpenStreetMap ones in order to prepare a data integration. It does not conflate much but is focused on initializing OpenStreetMap data structures using available information.
gtfs2osm
gtfs2osm is a web-based tool for to create transport data in OpenStreetMap using a GTFS. It has therefore some functions to compare the GTFS with the already existing OpenStreetMap data in order to avoid the creation of duplicates objects.
It is in the form of a script that creates web pages by recursively browsing GTFS objects. It takes as input a GTFS file and an OpenStreetMap database in
osm.pbfformat. We will look at the original version (originally thought for the Paris region) as well as a more recent version (thought for Luxembourg), although there is not really any specificity for some geographical area or network in this tool.The website proposes to explore the GTFS by first choosing a mode of transport (GTFS
route_type) among those available, then a transport agency, then a line (GTFSroute), then a line variant (GTFStrip, knowing that the trips entirely included in another are filtered out). It is on this line variant page that the use really begins.For each GTFS stop on this trip, several OpenStreetMap candidates objects are explored by the script, which will finally choose the closest OpenStreetMap stop, or a nearby stop with exactly the same name, or nothing if no candidates are found.
The search for candidate OpenStreetMap objects is based on several tags chosen according to the mode of transport, in order to take into account the diversity of contributions in OpenStreetMap (where several transport models coexist)
Only one candidate is presented, with information on the distance and similarity of the name. The user can then import this object into JOSM OpenStreetMap editor, and automatically add an additional number of tags.
The user can also create in one click in JOSM the OpenStreetMap object corresponding to the trip (a
routerelation) based on the information present in the GTFS.Going up in the breadcrumb trail, the user is returned to the line page, where they are shown the OpenStreetMap objects that could match (
route_masterrelations) with a matching mode of transport, line number and transport network, or with a matching identifier present in both OpenStreetMap and GTFS. If no candidate is found, the user can create the OpenStreetMap object in JOSM in one click using the information from the GTFS.gtfs2osm source code is in Perl and licensed under GPL v3.
ref-lignes-stif
ref-lignes-stif (also called STIF-to-OSM) is a web interface to compare and add unique identifier to OpenStreetMap transport objects in Île-de-France (Paris region).
The local authority of the Paris region (who was called STIF when the tool was initially released) has defined unique identifiers for each public transport line (~ 1800) and stop (~40 000). The tool helps OSM contributors to add these identifiers to OpenStreetMap objects in a guided workflow: matching lines, then line variants, then stops. It is a web tool and it uses Overpass web service to query OpenStreetMap and navitia.io API to get public transport objects.
The entry point is a searchable list of lines from OpenStreetMap. When you select a line, the tools presents you open data candidates based on the line number. For the 91-10 bus line, you will only get one candidate while for a bus line labelled “2” you will get 19 results to review.
For each candidate, you can review its attributes, its shape and its stops from both OpenStreetMap et Paris region open data.
The user has to choose the best match within the proposals: the open data line identifier will be retrieved and added to OpenStreetMap, and the user will access the line variant review page.
On this page, you get the list of the line variants from OpenStreetMap and you have to choose between the line variants from the open dataset. In most cases, in both OpenStreetMap and the open dataset, the line variants have their origin and destination as labels, so you can easily choose the good one. A debug page is available to see the shapes and stops from OpenStreetMap and the stops from the open dataset for each line variant to help the user to make the right choice.
As there is no line variant identifier in the open dataset, no identifier is added to OpenStreetMap, but the user can then access the stop review page.
On the stop review page, you get the list of the stops of the chosen line variant, and for each one, the closest open data stop which is served by the open data line variant previously chosen. You can compare their names and distance and automatically retrieve and add the open data identifier in OpenStreetMap to the stop.
The web tool comes along with debug tools for each step:
The source code is in Javascript and released under the MIT license.
Tartare-tools
Tartare-tools is a library to read transport data and perform format conversion. It also has some functions to improve data using OpenStreetMap data. It was developed by Kisio Digital, a French company that provides digital services to simplify travel for passengers.
It takes as input a transport dataset in a custom format and an OpenStreetMap database in
.osm.pbfformat. It canThe library has a function to automatically match the transport objects (lines, line variants and stops) to OpenStreetMap objects but you can also provide some or all matchings to use the enhancements functions.
You need to provide as configuration the matching between the transport dataset network and OpenStreetMap network.
The library will first match OpenStreetMap lines (as route_master relation objects) using:
reftag from OpenStreetMapIf there is only one candidate, it will then match the line variants (called
routein the library, as in OpenStreetMap) with OpenStreetMap line variant (as route relation objects) using:totag from OpenStreetMap routesIf there is only one candidate, it will then match the stops of the line variant with OpenStreetMap stops using the name. As for other objects, the matching is valid only if there is only one candidate.
The library is designed to require very little configuration (only network matching) and has very strict conditions to limit false positives. It is therefore not necessarily intended to match the entirety of the objects. The number of objects actually matched will depend on the quality of the OpenStreetMap data in terms of conformity to the model, completeness and uniformity of the attributes filled in.
Tartare-tools source code is in Rust and licensed under GPL v3.
Other approaches
Sophox
Sophox is a web tool that allows to query OpenStreetMap data, some OpenStreetMap metadata and Wikidata data at the same time. It stores all these data in a structured semantic way, using
subject predicate objectstatements.By doing cross queries, it allows, for example, to find similar objects in OpenStreetMap and Wikidata using a common identifier (the Wikidata identifier) and to compare their attributes. For example, here is a query comparing the attributes of subway lines:
Using this approach for conflation seems complex, but it could help identify errors or generate new composite datasets mixing sources.
Sophox source code is licensed under Apache-2.0.
Transitland onestop ID
Transitland is a community edited website and webservices aggregating transport databases. To link datasets, operators, stops and routes across disparate sources, it uses a mechanism called “Onestop ID scheme”.
This mechanism consists of assigning a unique, perennial and readable identifier, independent of the identifiers already present in the source data. It is mainly based on a geohash and an abbreviated name and is not really designed to effectively compare and merge datasets.
Map matching tools
In the context of comparing and improving data from different sources, the practice of map matching is also sometimes used.
This generally involves bringing together data of quite different natures (usually a series of geographic coordinates and a road or rail network). For example, several tools attempt to use the OpenStreetMap road network to complete transport routes independently of the structured transport data in OpenStreetMap.
The objectives are diverse but quite different from our use case:
Comparative review
There are two kinds of tools that use the logical and hierarchical structuring of transport data to improve the conflation process:
Those who start with stops (gtfs2osm, GO Sync, GTFS Integrate) match the stops from both sources using the methods described in the “conflating geographical points” paragraph above. Then they create the routes and lines if necessary using methods similar to those described in the “Conflating non geographical objects” paragraph.
The use case here is more focused on creating data in OpenStreetMap than on conflation. The main interest of these tools is in the ability to initialize OpenStreetMap objects using GTFS attributes and without necessarily having a deep knowledge of the GTFS format.
Starting with the stops is also a form of prerequisite because the stops are needed to create the objects representing the lines in OpenStreetMap.
In contrast, those that start with lines are more focused on conflation than on creation of missing data.
The main interest of this approach is for bus stops, where associating stops on either side of the road (which have a close distance and similar attributes) is unefficient with traditional point conflation approaches. By using the line variants that serve these stops, the risk of mismatching is therefore reduced.
The two tools studied have different approaches: Tartare-tools will rather minimize the risk of false positive, even if it means not proposing an association at all, while ref-lignes-stif will maximize the number of candidates proposed for each association in order to be able to find a match for each object, even if it means having the user make all the choices and spend a lot of time at it.
In any case, these tools offer interesting insights on visualizing transport data from various sources.
Conclusion
There are well-established mechanisms for performing data conflation:
In the case of transport data, using the transport model hierarchy greatly improves the quality of the process by limiting false positives, but may be sensitive to modeling discrepancies.
Using an identifier to link datasets is a proven technique found almost systematically. It is also a good solution for maintenance over time, which is critical for a database edited collaboratively by several actors and very relevant in the context of evolving transport data.
While many tools exist in OpenStreetMap and Wikidata collaborative databases ecosystems, no single tool can meet all needs, due to the diversity of use cases.
The main choice to be made according to the use case will be to propose several candidates for each object (which implies a more or less long and tedious work of reviewing each element) or, conversely, to assign the best candidate to each object.
A review may remain proposed in any cases, and may be collaborative or not.
Whatever the algorithm and process, special attention must be paid to the visualization of the results, whether it is the individual debugging of the matching of one element, or the global visualization of the results and the percentage of objects in each category.
Credits
This study was carried out by Jungle Bus for MobilityData as part of the Mobility Database project.
This document is made available under the conditions of the CC-BY-SA license.

References